F:Elasticsearch是什么?
Elasticsearch 以前叫 Elastic Search。顾名思义,就是“弹性的搜索”。很明显,它一开始是围绕着搜索功能,打造了一个分布式搜索引擎,底层是基于开源的搜索引擎库 Lucene,是由 Java 语言编写的,项目大概是 2010 年 2 月份在 Github 正式落户的。
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。
关联词汇:
Lucene:Lucene 是一个非常古老的搜索引擎工具包,也是用 Java 编写,主要用来构建倒排索引(一种数据结构)和对这些索引进行检索,从而实现全文检索功能。 Lucene 很强大,使用起来也非常灵活,缺点是它仅仅是一个基础类库,也没有考虑到高并发和分布式的场景。如果你想在自己的程序里面使用 Lucene,还是需要做很多工作,并且涉及很多搜索原理和索引数据结构的知识,这就给我们带来了不少挑战。所以,Lucene 的上手时间一般都比较长。
RESTful 风格:RESTful是一种软件架构风格、设计风格,而不是标准,只是提供了一组设计原则和约束条件。它主要用于客户端和服务器交互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
Elasticsearch的发展史:
时间一晃来到 2004 年,有一个以色列小伙子,名字叫谢伊·班农( Shay Banon),他成亲不久来到伦敦,因为当时他的夫人正好在伦敦学厨师。
初来乍到,也没有找到工作,于是班农就打算写一个叫作 iCook 的小程序来管理和搜索菜谱,一来练练手,方便找工作;二来这个小工具还可以给其夫人用。
班农在编写 iCook 的过程中,使用了 Lucene,感受到了直接使用 Lucene 开发程序的各种暴击和痛苦,于是他在 Lucene 之上,封装了一个叫作 Compass 的程序框架,与 Hibernate 和 JPA 等 ORM 框架进行集成,通过操作对象的方式来自动地调用 Lucene 以构建索引。
这样做的好处是,可以很方便地实现对‘领域对象’进行索引的创建,并实现‘字段级别’的检索,以及实现‘全文搜索’功能。可以说,Compass 大大简化了给 Java 程序添加搜索功能的开发。Compass 开源出来,变得很流行。
在 Compass 编写到 2.x 版本的时候,社区里面出现了更多需求,比如需要有处理更多数据的能力以及分布式的设计。班农发现只有重写 Compass ,才能更好地实现这些分布式搜索的需求,于是 Compass 3.0 就没有了,取而代之的是一个全新的项目,也就是 Elasticsearch。
A:Elasticsearch的优势
- Elasticsearch 作为一个独立的搜索服务器,提供了非常方便的搜索功能。用户完全不用关心底层 Lucene 的细节,只需要通过标准的 Http+RESTful 风格的 API,就可以进行索引数据的增删改查。数据的输入输出采用 JSON 格式,以文档和面向对象的方式,这样就能非常方便地理解和表达领域数据。
- 同时,Elasticsearch 基于分片和副本的方式实现了一个分布式的 Lucene Directory,再结合Map-reduce 的理念,实现了一个简单的搜索请求分发合并的策略,能轻松化解海量索引和分布式高可用的问题。
仅仅依靠这两点,Elasticsearch就已经秒杀了当时市面上所有的搜索引擎服务或是程序库。
如今,Elasticsearch 基本上已经是搜索引擎市场排名第一的产品了,从 DB-Engines 网站的排名可以看到,Elasitcsearch 基本上是一骑绝红尘,拉开第二名远远一大截。
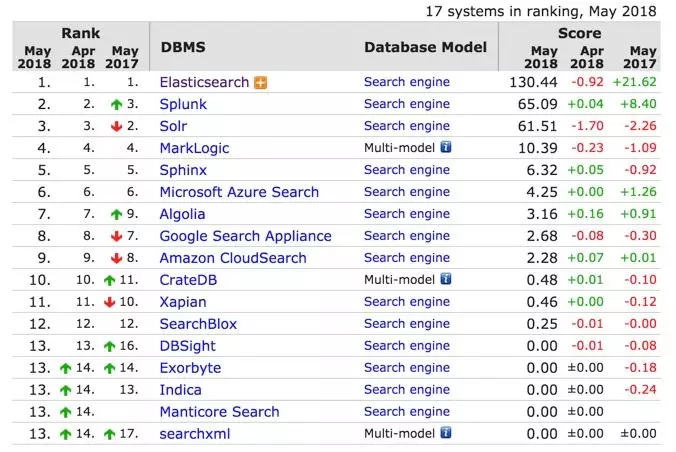
统计数据来源:https://db-engines.com/en/ranking/search+engine
BE:Elasticsearch的应用场景和带来的价值-ELK的出现
Logstash:Logstash 是一个开源的日志处理工具,用 JRuby 写的,主要特点是基于灵活的 Pipeline 管道架构来处理数据。可以理解为将数据放进一个管道内进行处理,并且就跟真正的自来水管一样,管道由一截一截管子组成,每一个小管代表着一个数据处理的流程,每一个流程只做一件事情,然后可以根据数据的处理需要,选择多个不同类型的管子灵活组装。
Logstash 社区非常活跃,支持多种输入数据源和多种输出数据源。一开始, Elasticsearch 只是作为其中一个输出的存储,主要用于日志数据的存储。
不过,随着大家把日志发送到 Elasticsearch 之后,大家发现这家伙用起来很方便嘛,不仅能够存储大量的数据,水平伸缩还很方便。更关键的是,你能够很方便地把数据找出来,也就是进行全文搜索。
全文搜索在日志分析里面是非常基础的一个功能,通过一个关键字就能定位具体的详细日志,相比存放到关系型数据库和普通的文件存储,Elasticsearch 优势非常明显。于是 Logstash 搭配 Elasticsearch 变得很受欢迎。
Kibana:Logstash 自带的 UI 查询日志的界面有点简陋,于是有一个叫作 Rashid Khan 的运维工程师表示完全忍不了了,用 PHP 写了一个叫作 Kibana 的程序,一个更好看和更好用的前端界面。PHP 写完一版,他又用 Ruby 写一版,后面又用 AngularJS 写了一版,不仅有日志的搜索和查看,还加上了一些统计展示功能。Kibana 的名字其实是俩个水果的名字的组合(Kiwi+Banana)。
这个时候,Elasticsearch 已经有 Facet 概念,也就是分面统计( 注:1.0 之后推出了 Aggregation 来代替 Facet),可以对数据里面的某个字段进行单个维度的统计,支持多种统计类型。比如, TermFacet 可以计算字段里面某些值出现了多少次;Histogram Facet 还可以按时间区间进行汇总统计等。这些统计功能在前端 UI 就可以被利用起来,展示一些饼图、时间曲线等等,在运维的分析里面自然也都是需要的。慢慢的 Kibana 越做越复杂,支持的功能越来越多,Kibana 3 变得流行起来。于是乎,ELK 横空出世(Elasticsearch、Logstash 和 Kibana 这三个产品的首字母缩写),风靡了整个运维界。
Beats:Elastic 后面又引入了 Beats 家族。这是一系列非常轻量级的数据收集端,介绍几个比较典型的,比如:
-
Packetbeat 可以实时监听网卡流量,并实时解析网络协议数据,可用来做 NPM 网络数据分析;
-
Metricbeat 可以用来收集服务器,以及服务器上部署的应用服务的各项监控指标数据,这样就可以替代 Zabbix 等传统的监控软件,来做服务器的性能指标分析;
-
Auditbeat可以实时收集服务器的行为事件,用于安全方面的入侵检测和安全日志审计分析;
-
Winlogbeat用于 Windows 平台的事件日志收集;
-
Filebeat 用于日志文件的收集等。
Elasticsearch、Logstash、Kibana、Beats ,这几个放在一起,就叫作 Elastic Stack。
如今,Elastic 的版图越来越大,前年,Elastic 收购 Opbeat,开源了业界第一个完整的 APM 解决方案,通过探针可以实现无侵入的代码级别的应用性能监控;
去年7月又收购了代码搜索 Insight.IO,后续可以实现代码级别的语义检索。今年又收购了一个做终端安全的厂商 Endgame。这样 Elastic Stack 这一个平台就可以同时做到:
-
日志分析
-
性能指标分析
-
安全日志分析
-
APM 应用性能分析
-
NPM 网络性能分析
-
网站站内搜索
-
企业级搜索
-
代码搜索
-
实时 BI 业务分析
-
SIEM 解决方案
-
终端设备安全
-
......
整理自:https://mp.weixin.qq.com/s/c5l8dJvReXIblt-cbEv0YA